As the scope, size, and feature set of your React + Redux application grows, so does the pain of maintaining it, especially when you're working with a big team, and multiple people work on each feature in your application. In this article, we are going to be exploring how to organize your codebase, to increase maintainability and extensibility.

When you first start writing a new React application, the feature set is small, and the React API is simple, yet flexible and powerful enough to handle state management. Eventually however, your application grows bigger, and the shortcomings of React's setState at handling state management for larger applications become obvious, in a painful manner.
So you do a bit of research and figure out Redux is your best bet at handling the growing state management needs of your application. Redux introduces actions, actionCreators, reducers, middleware and stores. And since this is a React application, you'll need to wire Redux to your React components, so you'll also want to use React-Redux. Add all these up, and your application can quickly become a huge mess of spaghetti code, unless you organize your application properly.
Ensuring that your application is organized properly, in a manner that is easy to understand for your entire team, can save you a lot of time, and resources while maintaining and extending the application. I have been writing React applications for the past three+ years, with these applications ranging in complexity from trivial to ultra-complex.
Over the course of developing these applications, I have experimented with multiple ways of organizing my React applications, and I think I've finally settled on the pattern that provides the best balance of ease-of-use and maintainability. I call this pattern of organizing my application, the State-View pattern. But before, we look at the State-View pattern, let's first look at the other patterns that I went through, and why I found them lacking.
Grouping by Function/Type of File
In a React + Redux application, we can have multiple different types of files, each of which perform a specific function. For example, we have reducers which derive a new state from the given state and an action, actionCreators which create the action to pass on to the reducers, the store which holds the state of the application, and allows components to subscribe to changes to the store, the presentational components which create the views that are rendered on the screen, the container components which do the bulk of the heavy lifting and provide the business logic, persistence etc.
The most common way to organize a React + Redux application, is to simply group your files by the type/function of that file. This is how a vast majority of React + Redux applications are organized. If you look at the Real-World example, from the Redux Github repository, you'll see that this is how it is organized.
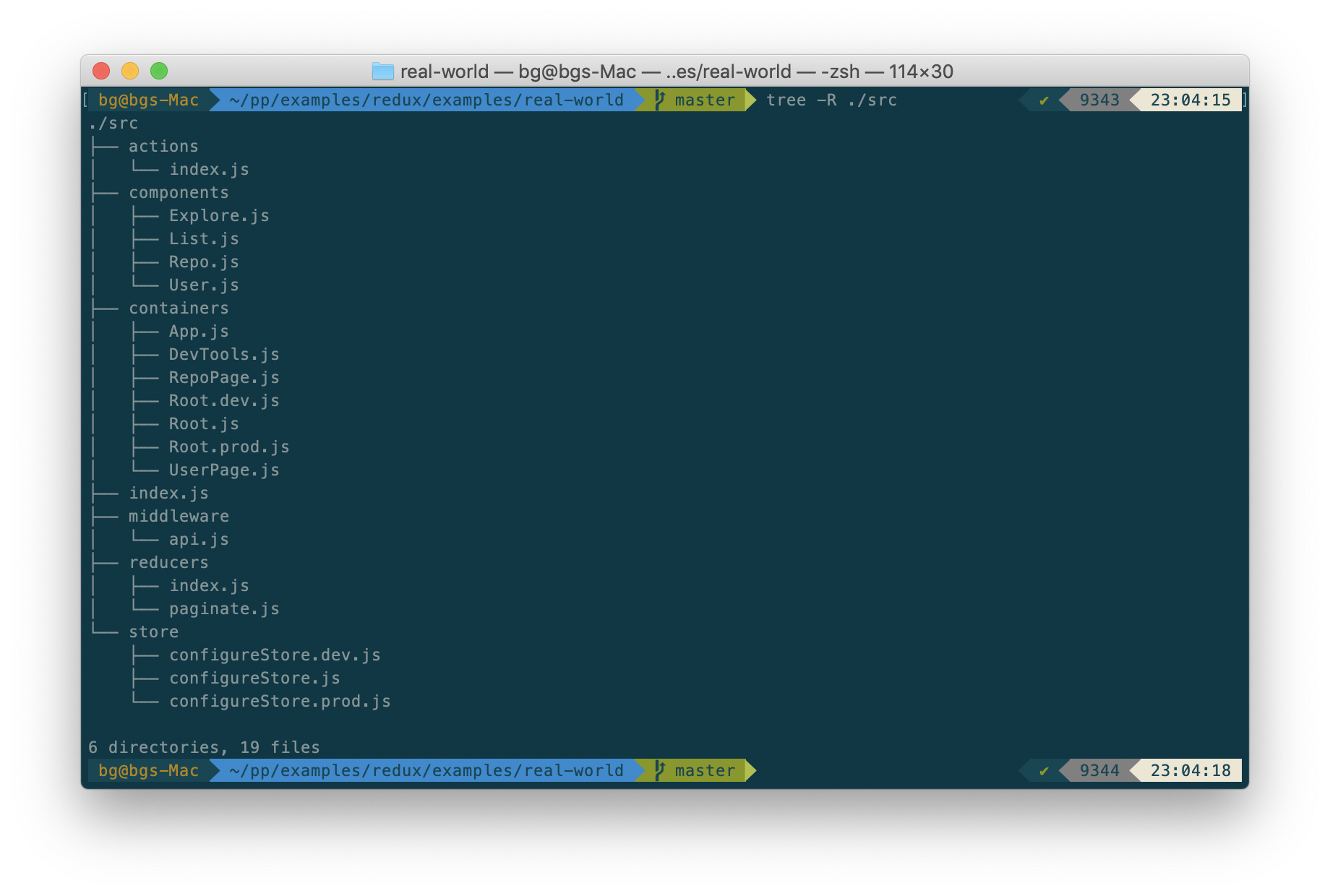
In the real-world example project:
configureStore.dev.js,configureStore.prod.jsare twostores(only one of which is used based on the running environment of the application), and these are grouped under thestoredirectory.index.jsandpaginate.jsboth export multiple reducers, and these are grouped together under thereducersdirectory.api.jsprovides a Redux middleware, which is used to make API calls to Github's API, and normalize the results. This is located under themiddlewaredirectory.- The various
container componentsare grouped together under thecontainersdirectory. - The various
presentational componentsare grouped together under thecomponentsdirectory. - The actions are all defined in a single
index.jswhich is placed under theactionsdirectory. - The entry point of the application
index.jsis placed directly at the root.
The advantage of organizing your application by grouping files with the same function together, is that you always know exactly where a specific type of file is going to be. For example: If you are debugging an issue with state transitions not happening correctly, you know that the only place where a state transition can happen is within a reducer, and all reducers are located in the reducers directory.
This works well as long as your application is small and has only a few components and associated actions, reducers and middleware. As your application becomes bigger, you will find yourself dumping more and more files which are only tangentially related to each other in the same directory, and going through these files to isolate specific issues will start consuming more of your time and resources. This is only exacerbated, when multiple developers are working on the same codebase, and are all touching the same files in the same directory to get their own individual features working.
Grouping by Application Feature
The main problem with the 'Function/Type based grouping' approach to organizing your codebase, is that to work on a single feature, you will have to work on files which are distributed across your entire project, in multiple unrelated directories. In order to alleviate this problem, you can instead organize your React + Redux application by grouping files related to a specific feature of your application together.
Modifying the same Redux Real-World example to group by application feature would make it look like this:
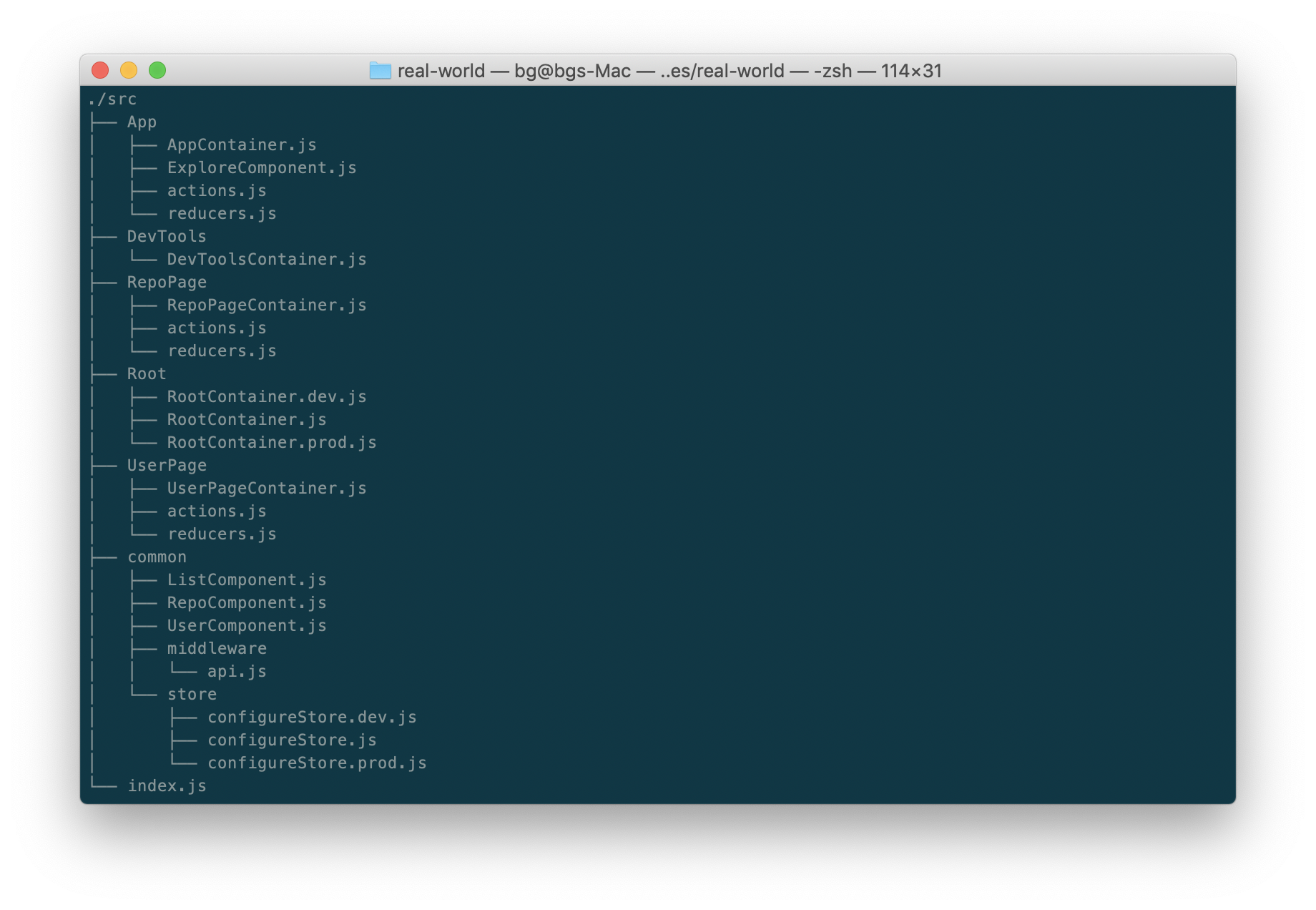
Here we have split up our code into different 'features':
Root- The root container component which performs routing and renders other components. Since this does not maintain or manage state, it does not have anyactionsorreducersin the directory. We have also renamed the container component and suffixed the file withContainerto indicate it as acontainercomponent.App- The main application component. Since this does maintain a state to indicate whether or not the API call errored out, it hasactions.jsandreducers.jsin the directory. You may notice we have renamed theExplorecomponent toExploreComponent. This is to indicate this as a presentational component.DevTools- Is responsible for the DevTools which log the state as it transitions with each action. Does not manage any state of it's own, so this directory only has the components.RepoPageandUserPage- These directories correspond to theRepoPagefeature which lists the starred watchers of a repo, and aUserPagefeature which lists the repos a user has. These components manage their own state, specifically they manage the propertiesentitiesandpaginationof the applicate state object. Remember, this as it will become important shortly.common- Anycomponent,middleware,reduceroractionthat is shared across multiple features goes here.
This is already looking so much better than 'Function/Type based grouping'. If we want to work on a particular feature, all the files related to that feature are in the same directory. This includes the actions, reducers, presentational components and container components. Both view and state related code is sitting in the same directory, thus making it quite easy for us to make changes for a specific feature, without having to go and modify five different files in five different directories.
This approach usually works well for those applications where there is a one-to-one mapping between state items and view. For example, in a todo list, each todo item is only ever displayed in one location on the screen, via a single presentational component. Thus we are able to segregate the state of the application cleanly based on the feature that makes use of that state, and we can group the related actions and reducers together with the view components for that feature.
But what happens when the mapping between state items and view components is not one-to-one. This is exactly what happens in the case of the 'real-world redux example' application we are analyzing. In this application, both RepoPage and UserPage functionality, independently make use of the entities and pagination properties on the state object. Both the features read and write to these properties, by sharing the same actions and reducers between them.
In such a case how do we group the state and the view together? Which actions and reducers should be grouped with RepoPage and which should be grouped with UserPage? Grouping the state related code, mainly the actions and reducers with either one feature, breaks our grouping model, and it is no longer true that we always have all the code related to a specific functionality in a single directory. Putting the actions and reducers in common also results in the exact same issue.
The State-View Pattern
Recently, I've been working on a pretty complex React + Redux application, for which I experimented with a new pattern of organizing my application's codebase. This is an evolution of the 'feature-based grouping' approach to organizing your code. Pretty much the only issue (albeit a major one), of the feature-based grouping approach, is unpredictability with regards to state, when the state does not map one-to-one with views.
In order to eliminate this unpredictability, we split the codebase into two seperate main directories, and files are grouped based on different factors in each directory. As you may have guessed, these two directories are the state and the view directories.
All state management related code, including all actions, reducers, middleware and stores are put into the state directory. All other code is put into the view directory. So how are these directories further organized?
Let's first look at how the overall application structure looks when the real-world Redux example is rewritten to use the State-View pattern:
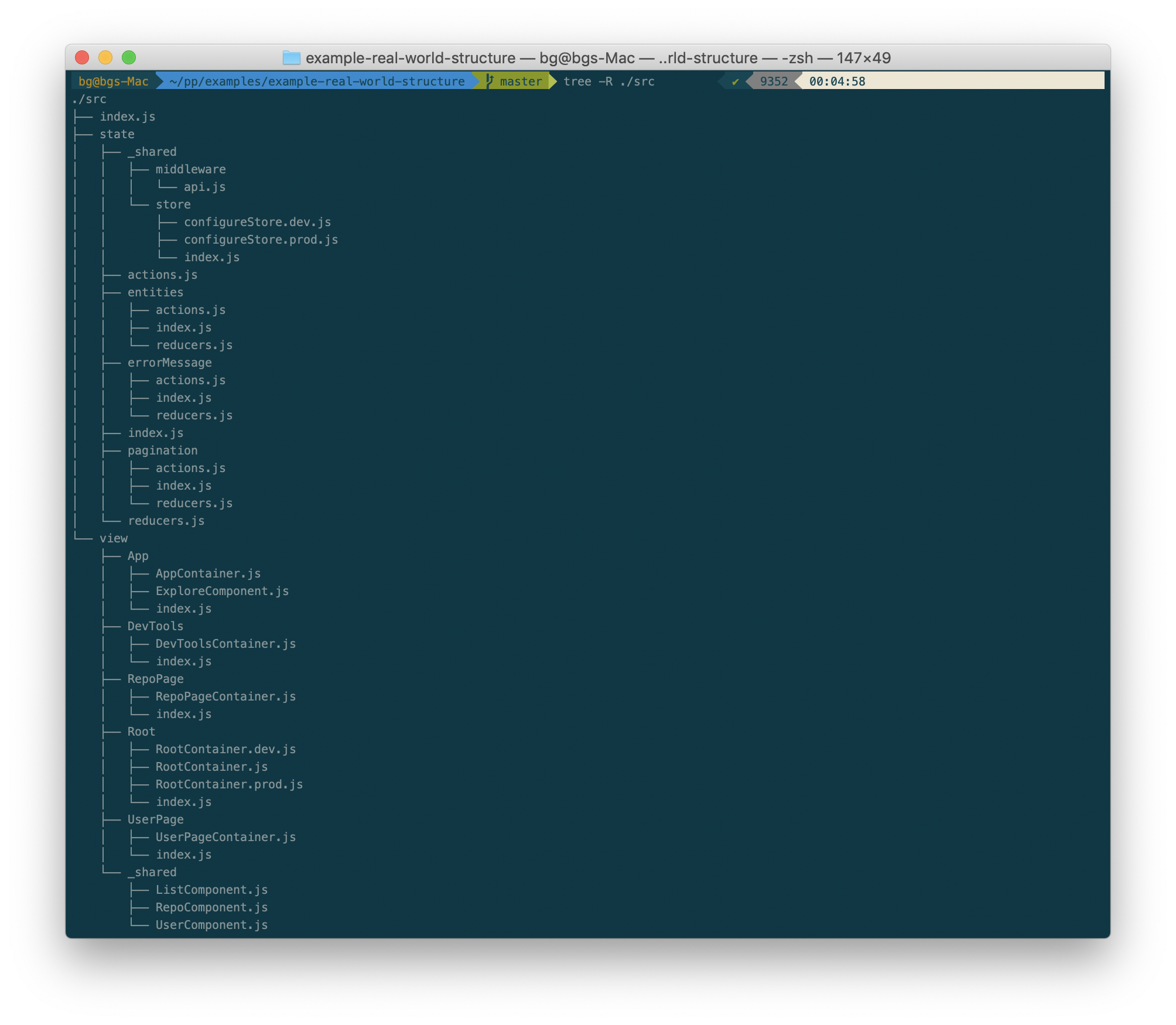
There are the two main directories state and view. Let's explore the view directory first.
Root- The root container component which performs routing and renders other components. All state management related code is removed from here, and only view specific code is retained. We have also renamed the container component and suffixed the file withContainerto indicate it as acontainercomponent.App- The main application component. You may notice we have renamed theExplorecomponent toExploreComponent. This is to indicate this as a presentational component.DevTools- Is responsible for the DevTools which log the state as it transitions with each action.RepoPageandUserPage- These directories correspond to theRepoPagefeature which lists the starred watchers of a repo, and aUserPagefeature which lists the repos a user has. As you can see, these directories only contain the view components and allactionsandreducershave been removed._shared- All the view components which are shared between multiple features, are grouped together here.
As you can see the view directory is organized extremely similarly to how the application is organized in the feature-based grouping pattern. The reason for this is pretty simple. There was no real issue with the way the view components were organized in the feature-based grouping pattern, so we just left it as is.
Now let's look at the state directory. This is where the majority of the changes from the feature-based grouping pattern occur. First off, you will notice that the names of the subdirectories inside the view directory do not at all correspond with those of the subdirectories inside the state directory. This is completely intentional, and is done to enforce the idea that the state does not have a one-to-one mapping with the view.
Instead of organizing the state directories contents by application feature, we organize them by the properties of the store that they are responsible for. In the real-world redux example, the state of the application looks something like this:
const state = {
errorMessage: null,
entities: {},
pagination: {}
};
If we go back to the state directory, the subdirectories correspond to the properties of the state. Each subdirectory contains the actions and reducers required for manipulating that particular portion of the state. Any commonly shared items, are placed in the _shared directory. These actions and reducers are then rolled up and combined, by using the actions.js and reducers.js files in the state directory, and they are then exported by the index.js. So now, if we need to use a specific action in any of our view components, we can require it like this:
import { actions } from '../../state';
const { loadRepo, loadStargazers } = actions;
If you want to have a look at the code for the state-view pattern for the real-world redux example application, the source for that is available on Github.
Thus we have effectively decoupled the way our state related code is organized from the way our view related code is organized. Since state is now no longer grouped together with views, we again have a very predictable pattern for our code. Any view related code will always be in the corresponding feature subdirectory in the view directory. Any state manipulation performed by those views will be in the subdirectory with the corresponding state property name in the state directory. Thus so long as you know where your view is (which should be easy to figure out based on the feature it is part of), you can easily figure out what state it impacts and where the corresponding state manipulation code resides.
Hoorah! We have restored predictability to our React + Redux application's structure, and this should enable us to maintain and extend our application, a lot easier than we could have done it before.
I'd love to hear your opinion on things I've written in this article. Unfortunately, I've not yet found a nice lightweight comments widget to add on to my blog, so until then the only way I can take comments is via email. Do write to me at asleepysamurai at google's mail service.